How to install Hadoop Hive on CentOS7
What is Hive
Hive is a data warehouse infrastructure tool to process structured data in Hadoop. It resides on top of Hadoop to summarize Big Data, and makes querying and analyzing easy.
Initially Hive was developed by Facebook, later the Apache Software Foundation took it up and developed it further as an open source under the name Apache Hive. It is used by different companies. For example, Amazon uses it in Amazon Elastic MapReduce.
Hive is not
- A relational database
- A design for OnLine Transaction Processing (OLTP)
- A language for real-time queries and row-level updates
- It stores schema in a database and processed data into HDFS.
- It is designed for OLAP.
- It provides SQL type language for querying called HiveQL or HQL.
- It is familiar, fast, scalable, and extensible.
The following component diagram depicts the architecture of Hive: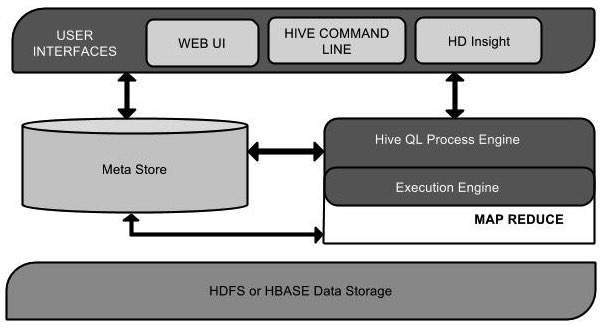
Requirements: Install JAVA and Hadoop
Apache Hive2.1 requires java 7 or later version. We also
need to install hadoop first before installing apache hive on our system. In
example below, I'm using java 8
$ java -version
java version "1.8.0_92"
Java(TM) SE Runtime Environment (build 1.8.0_92-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.92-b14, mixed mode)
java version "1.8.0_92"
Java(TM) SE Runtime Environment (build 1.8.0_92-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.92-b14, mixed mode)
Download Hive package
After configuring hadoop successfully on your linux system.
lets start hive setup. First download latest hive source code and extract
archive using following commands.
$ cd /opt/hadoop
$ wget
http://archive.apache.org/dist/hive/hive-2.1.0/apache-hive-2.1.0-bin.tar.gz
$ tar xzf apache-hive-2.1.0-bin.tar.gz
$ mv hive-2.1.0-bin hive
$ chown hadoop -R hive
$ mv hive-2.1.0-bin hive
$ chown hadoop -R hive
Setup Environment Variables
Beside Hadoop environments, there are two more environment
variables you need to add to ~.bashrc
# su - hadoop
export HIVE_HOME=/opt/hadoop/hive
export PATH=$HIVE_HOME/bin:$PATH
Preparation before starting Hive
Create /tmp and /user/hive/warehouse and
set them chmod g+w in HDFS.
$ hdfs dfs -mkdir /tmp
$ hdfs dfs -mkdir /user/hive/warehouse
$ hdfs dfs -chmod g+w /tmp
$ hdfs dfs -chmod g+w /user/hive/warehouse
Hive metastore schema initialization
On Hive2.1.0, it's required to initialize metastore schema
before hive starts, in the case below, I used db type derby
$ schematool -dbType derby -initSchemaTo 2.0.0 -verbose
which: no hbase in (/opt/hadoop/hive/bin:/usr/lib64/qt-3.3/bin:/bin:/usr/bin:/usr/X11R6/bin:/opt/local/bin:/usr/local/bin:/opt/hadoop/hadoop-2.7.3/sbin:/opt/hadoop/hadoop-2.7.3/bin:/home/hadoop/.local/bin:/home/hadoop/bin:/opt/hadoop/hadoop-2.7.3/sbin:/opt/hadoop/hadoop-2.7.3/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true
Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver
Metastore connection User: APP
Starting metastore schema initialization to 2.0.0
Initialization script hive-schema-2.0.0.derby.sql
Connecting to jdbc:derby:;databaseName=metastore_db;create=true
Connected to: Apache Derby (version 10.10.2.0 - (1582446))
Driver: Apache Derby Embedded JDBC Driver (version 10.10.2.0 - (1582446))
Transaction isolation: TRANSACTION_READ_COMMITTED
0: jdbc:derby:> !autocommit on
Autocommit status: true
0: jdbc:derby:> CREATE FUNCTION "APP"."NUCLEUS_ASCII" (C CHAR(1)) RETURNS INTEGER LANGUAGE JAVA PARAMETER STYLE JAVA READS SQL DATA CALLED ON NULL INPUT EXTERNAL NAME 'org.datanucleus.store.rdbms.adapter.DerbySQLFunction.ascii'
No rows affected (0.374 seconds)
which: no hbase in (/opt/hadoop/hive/bin:/usr/lib64/qt-3.3/bin:/bin:/usr/bin:/usr/X11R6/bin:/opt/local/bin:/usr/local/bin:/opt/hadoop/hadoop-2.7.3/sbin:/opt/hadoop/hadoop-2.7.3/bin:/home/hadoop/.local/bin:/home/hadoop/bin:/opt/hadoop/hadoop-2.7.3/sbin:/opt/hadoop/hadoop-2.7.3/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true
Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver
Metastore connection User: APP
Starting metastore schema initialization to 2.0.0
Initialization script hive-schema-2.0.0.derby.sql
Connecting to jdbc:derby:;databaseName=metastore_db;create=true
Connected to: Apache Derby (version 10.10.2.0 - (1582446))
Driver: Apache Derby Embedded JDBC Driver (version 10.10.2.0 - (1582446))
Transaction isolation: TRANSACTION_READ_COMMITTED
0: jdbc:derby:> !autocommit on
Autocommit status: true
0: jdbc:derby:> CREATE FUNCTION "APP"."NUCLEUS_ASCII" (C CHAR(1)) RETURNS INTEGER LANGUAGE JAVA PARAMETER STYLE JAVA READS SQL DATA CALLED ON NULL INPUT EXTERNAL NAME 'org.datanucleus.store.rdbms.adapter.DerbySQLFunction.ascii'
No rows affected (0.374 seconds)
Note:
You may have noticed that I initialized the schema to version
2.0.0 instead of 2.1.0, why?
This is caused old known problem of Hive, new release of
Hive quite often missing the latest version of db schema support. To avoid
that, just use previous release.
Here is the example error output when using version 2.1.0
$ schematool -dbType derby -initSchemaTo 2.1.0 -verbose
which: no hbase in (/opt/hadoop/hive/bin:/usr/lib64/qt-3.3/bin:/bin:/usr/bin:/usr/X11R6/bin:/opt/local/bin:/usr/local/bin:/opt/hadoop/hadoop-2.7.3/sbin:/opt/hadoop/hadoop-2.7.3/bin:/home/hadoop/.local/bin:/home/hadoop/bin:/opt/hadoop/hadoop-2.7.3/sbin:/opt/hadoop/hadoop-2.7.3/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true
Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver
Metastore connection User: APP
Starting metastore schema initialization to 2.1.0
org.apache.hadoop.hive.metastore.HiveMetaException: Unknown version specified for initialization: 2.1.0
org.apache.hadoop.hive.metastore.HiveMetaException: Unknown version specified for initialization: 2.1.0
at org.apache.hadoop.hive.metastore.MetaStoreSchemaInfo.generateInitFileName(MetaStoreSchemaInfo.java:128)
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:282)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:508)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
*** schemaTool failed ***
Tips:
In old Hive version, you don't have init metastore schema,
so if you accidently ran hive before schema initialization, you may see error
like below:
Error: FUNCTION 'NUCLEUS_ASCII' already exists.
(state=X0Y68,code=30000)
Here is the fix for it
rm -f
$HIVE_HOME/scripts/metastore/upgrade/derby/hive-schema-2.1.0.derby.sql
then re init Hive metastore schema
Start Hive
Lets start using hive using following command.
$ hive
which: no hbase in (/opt/hadoop/hive/bin:/usr/lib64/qt-3.3/bin:/bin:/usr/bin:/usr/X11R6/bin:/opt/local/bin:/usr/local/bin:/opt/hadoop/hadoop-2.7.3/sbin:/opt/hadoop/hadoop-2.7.3/bin:/home/hadoop/.local/bin:/home/hadoop/bin:/opt/hadoop/hadoop-2.7.3/sbin:/opt/hadoop/hadoop-2.7.3/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/hadoop/hive/lib/hive-common-2.1.0.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
$ hive >
which: no hbase in (/opt/hadoop/hive/bin:/usr/lib64/qt-3.3/bin:/bin:/usr/bin:/usr/X11R6/bin:/opt/local/bin:/usr/local/bin:/opt/hadoop/hadoop-2.7.3/sbin:/opt/hadoop/hadoop-2.7.3/bin:/home/hadoop/.local/bin:/home/hadoop/bin:/opt/hadoop/hadoop-2.7.3/sbin:/opt/hadoop/hadoop-2.7.3/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/hadoop/hive/lib/hive-common-2.1.0.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
$ hive >
Create test Table
At this stage you have successfully installed hive. Lets
create a sample table using following command
hive> CREATE TABLE
test (id int, name string, age int);
OK
Time taken: 1.223 seconds
Show the created tables with below command.
hive> SHOW TABLES;
OK
test
Time taken: 0.431 seconds, Fetched: 1 row(s)
Drop the table using below command.
hive> DROP TABLE test;
OK
Time taken: 1.393 seconds
Now you have Hadoop Hive installed and configured on your
Hadoop cluster!
http://fibrevillage.com/storage/649-how-to-install-hadoop-hive-on-rhel7-centos7
http://fibrevillage.com/storage/649-how-to-install-hadoop-hive-on-rhel7-centos7

Such a nice blog with the attractive reference links which give the basic ideas on the topic.
ReplyDeleteData Science and Data Analytics
Statistics For Business Analytics